2025-05-01 Our paper for applying SceneSense in the real world has been accepted to ICRA 2025! arxiv link
2024-09-18 Real-world SceneSense applications and model updates on ARXIV: https://arxiv.org/abs/2409.10681
2024-06-30 SceneSense accepted to IROS 2024!
ICRA 2025 Video


Method
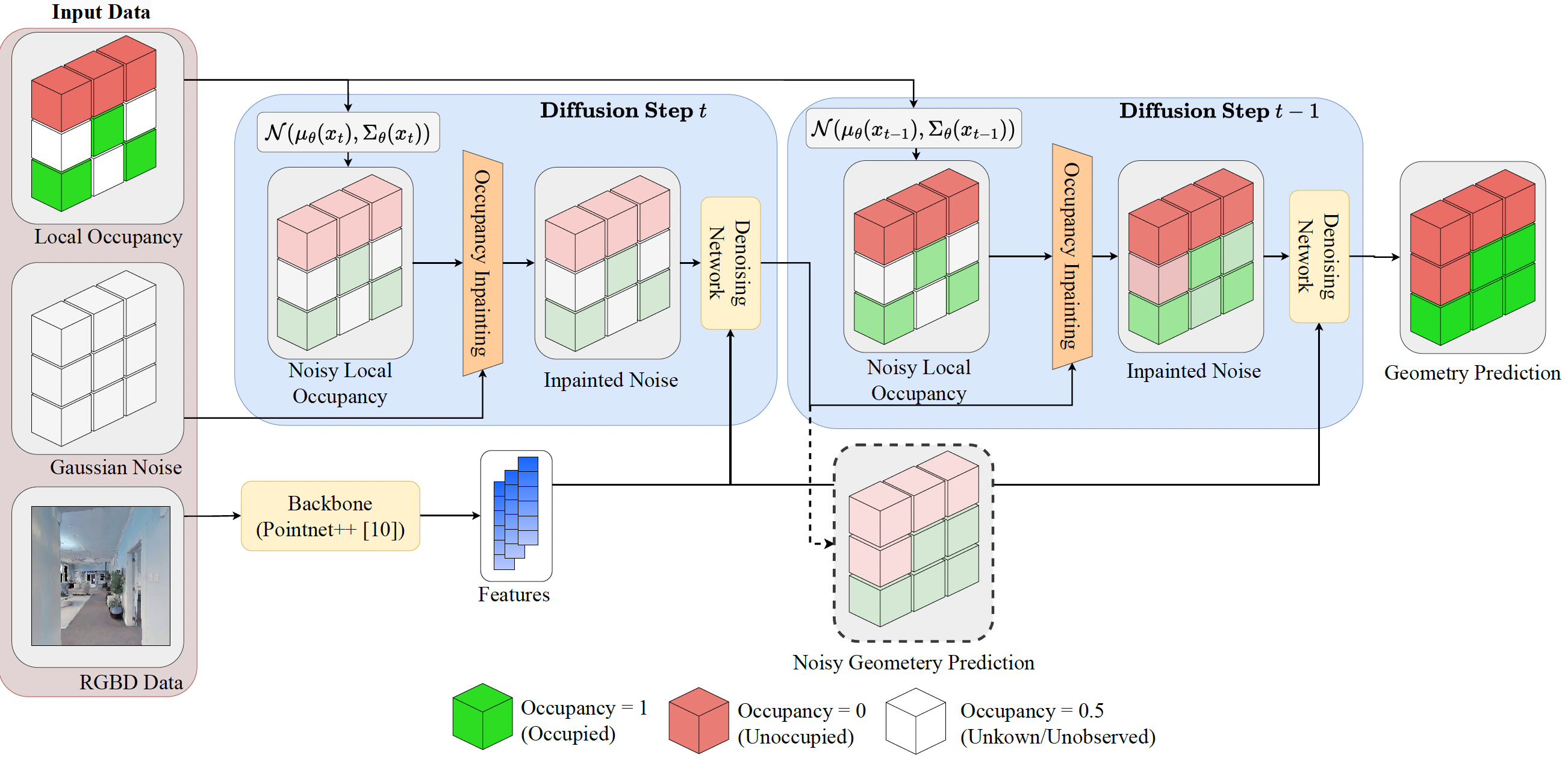
Our occupancy in-painting method ensures that observed space remains intact while integrating SceneSense predictions. Drawing inspiration from image inpainting techniques like image diffusion and guided image synthesis, our approach continuously incorporates known occupancy information during inference. To execute occupancy in-painting, we select a portion of the occupancy map for diffusion, generating masks for occupied and unoccupied voxels. These masks guide the diffusion process to modify only relevant voxels while introducing noise at each step. This iterative process, depicted below, enhances scene predictions’ accuracy while preventing the model from altering observed geometry.
IROS 2024 Video
Citation
@inproceedings{reed2024scenesense,
title={SceneSense: Diffusion Models for 3D Occupancy Synthesis from Partial Observation},
author={Reed, Alec and Crowe, Brendan and Albin, Doncey and Achey, Lorin and Hayes, Bradley and Heckman, Christoffer},
booktitle={2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
pages={7383--7390},
year={2024},
organization={IEEE}
}
@article{reed2024online,
title={Online Diffusion-Based 3D Occupancy Prediction at the Frontier with Probabilistic Map Reconciliation},
author={Reed, Alec and Achey, Lorin and Crowe, Brendan and Hayes, Bradley and Heckman, Christoffer},
journal={arXiv preprint arXiv:2409.10681},
year={2024}
}